TOP > SaaS > 自動化・AI活用 > 自動化 > AIインフラサービス
TOP > SaaS > 自動化・AI活用 > 自動化 > AIインフラサービス

記事更新日: 2026/02/24



AI開発プロジェクトの成否は、初期のインフラ選定で大きく左右されます。
生成AIやLLM(大規模言語モデル)開発には、従来のWebシステムとは全く異なる「計算資源」「データ基盤」「運用環境」が必要だからです。
一方で、AWSなどの汎用クラウドを使うべきか、特化型GPUクラウドを選ぶべきか判断に迷うケースも少なくありません。
本記事では、AIインフラを3つの階層で整理しながら、主要AIサービスを比較し、目的別の最適な選び方を専門的な視点で解説します。
目次
「AIインフラ」という言葉は広義に使われがちですが、単に高性能なサーバーを用意すれば成立するものではありません。
AI開発を成功させている企業は、どこに計算負荷が集中し、どこで運用コストや複雑性が増すのかを見極めたうえで、基盤全体を設計しています。
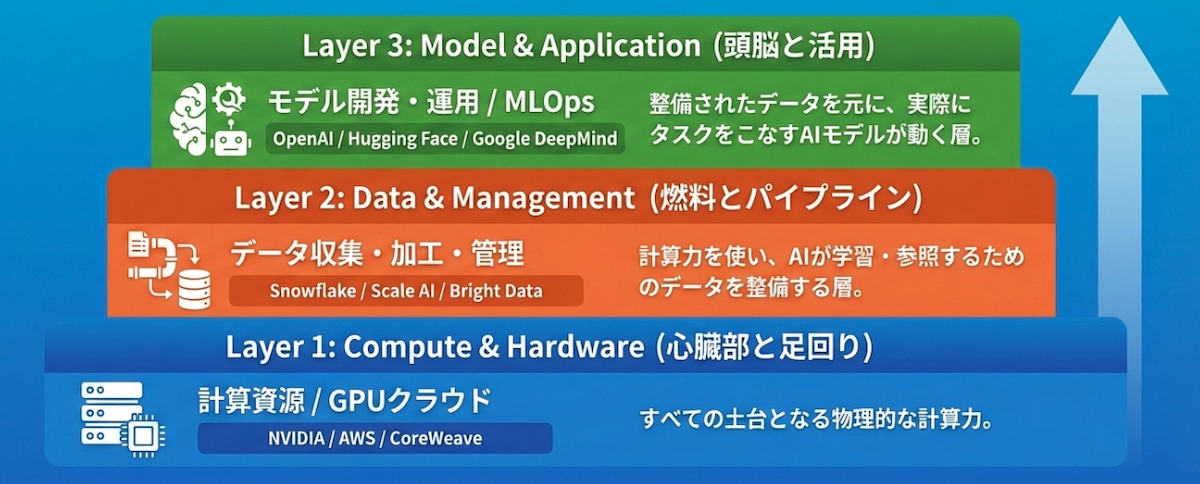
その考え方を整理する軸が「Compute (計算資源)」「Data (データ)」「Model (モデル)」の3階層です。
AIモデルの学習や推論を行うための「物理的なパワー」を提供する層です。
NVIDIA社のGPU(画像処理半導体)や、それらを搭載したサーバー、クラウド基盤が該当します。
計算速度と電力効率が最も重視されます。
AIに学習させるデータを管理する場所です。
社内データの統合だけでなく、Webからのデータ収集(スクレイピング)、アノテーション(タグ付け)、品質管理を行うための基盤が含まれます。
開発したAIモデルを管理・運用する層です。
LLMそのもののAPI利用や、モデルのバージョン管理、継続的な改善を行うためのMLOps(機械学習オペレーション)プラットフォームが求められます。
AIインフラは、下層から積み上げることで初めて機能します。
自社が今検討しているサービスが、どの階層に位置するのかを以下の図で整理しましょう。
まずはCompute Layerのサービスから紹介します。

画像出典元:「NVIDIA」公式HP
AI計算に不可欠なGPU(画像処理半導体)市場で圧倒的なシェアを持つリーディングカンパニーです。「H100」や「A100」などのチップは、LLM学習における事実上の業界標準となっています。
ハードウェアだけでなく、開発プラットフォーム「CUDA」のエコシステムを提供しており、多くのAIソフトウェアがNVIDIA環境を前提に設計されています。
最先端モデルの学習や研究用途など、計算性能と開発の安定性を求めるなら、NVIDIA製GPUの確保が最優先事項となります。
GPUハードウェアの価格は販売代理店や需給状況によって大きく変動します。
また、企業向けソフトウェアスイート「NVIDIA AI Enterprise」はライセンス形式(サブスクリプション)となります。
※詳細については、お問い合わせが必要です。

画像出典元:「AmazonWebService」公式HP
世界最大規模のクラウドプラットフォームであり、計算資源からストレージ、メットワークまでを包括的に提供します。
NVIDIA製GPUを搭載した高性能インスタンスに加え、自社開発のAI専用チップ「Trainium (学習用)」「Inferentia (推論用)」を展開し、コストと性能の選択肢を広げている点が特徴です。
既存システムとの連携、セキュリティ、フルマネージドの安心感を重視する企業に最適です。
GPUを「所有」するのではなく、「必要なときに使う」運用を前提とする場合、AWSは有力な選択肢になります。
基本は従量課金制(Pay-as-you-go)です。
GPUインスタンスは1時間あたり数ドル〜数十ドル程度が目安となり、長期利用向けにSavings Plansなどの割引制度も用意されています。

画像出典元:「CoreWeave」公式HP
AI特化型のクラウドプロバイダーです。
元々はマイニング事業を起点としており、現在はNVIDIAの出資を受けながら、Kubernetesネイティブな環境で大規模なGPUクラスターを柔軟に提供しています。
汎用クラウドのように多用途を前提としないため、H100などの最新チップの在庫を確保しやすく、かつ安価に提供できる構造を持っています。
コストを抑えて大規模学習を行いたい企業にとって、有力な選択肢となります。
GPUの種類と利用時間に応じた従量課金制です。
一般的に大手クラウドベンダーよりも安価な価格設定とされていますが、大口契約が中心です。
※詳細については、お問い合わせが必要です。
続いてData Layerです。

画像出典元:「Bright Data」公式HP
Web上の公開データを収集するための、世界最大級のプロキシネットワークおよびデータ提供プラットフォームです。
通常はアクセス制限やブロックの対象となりやすいWebサイトからも、コンプライアンスを遵守した形で大規模なデータ収集を可能にします。
自社独自のLLMやRAG構築における、「外部データ供給源」として機能します。
検索エンジンやニュース、ECサイトなど、Web上の情報を大量に学習させたいが、ブロックや法的リスクを回避したい場合に最適です。
従量課金(使用した帯域幅GB単位)または月額サブスクリプションプランがあります。
※プラン例:月額500ドル~ (従量単価が安くなる仕組み)
企業向けの大規模プランについては、個別見積もりが必要です。

画像出典元:「Snowflake」公式HP
企業内に分散・サイロ化したデータをクラウド上で一元管理できるデータウェアハウス(DWH)です。
高いセキュリティレベルでデータを統合できるほか、データを移動させずにその場でAI分析を行える「Snowflake Cortex」が強化されており、データガバナンスとAI活用を両立できます。
社内の基幹データや業務データを、安全かつスムーズにAIモデルと接続したい企業にとって中核となる基盤です。
「コンピュート(クレジット消費)」と「ストレージ(保存容量)」の組み合わせによる従量課金制です。
使用した分だけ支払うモデルで、リソースサイズによって消費クレジットが変わります。

画像出典元:「Scale AI」公式HP
高品質な学習データを作成するための「タグ付け(アノテーション)」や、人間によるフィードバック(RLHF)を提供する最大手企業です。
OpenAIやMetaなどのトップ企業も利用しており、AIモデルの回答を人間らしく、正確にするための「教師データ作成」を強みとしています。
AIモデルの回答精度を人間らしく調整したい場合に不可欠です。
エンタープライズ向けのプロジェクト単位での契約が一般的です。
データ量やタスクの難易度により変動します。
※詳細については、お問い合わせが必要です。
最後にModel Layerです。

画像出典元:「OpenAI」公式HP
ChatGPTやGPT-5シリーズを開発する、生成AI分野を代表する企業です。
自社でモデルやインフラを構築することなく、API経由で高性能なAIモデルを利用できる「Model as a Service」を提供しています。
テキスト生成に加え、画像生成や音声認識など幅広いタスクをカバーできる点が特徴です。
まずはスモールスタートで検証したい場合や、独自学習よりも即時性・精度を重視するタスクに適しています。
モデル運用の複雑さを極力抑えたい企業に向いた選択肢です。
API利用は、トークン数(文字数相当)に応じた完全従量課金制です。
ChatGPT Enterpriseは、ユーザー数ごとの月額ライセンス契約となり、詳細については、お問い合わせが必要です。

画像出典元:「Google DeepMind」公式HP
GoogleのAI研究部門として、Geminiや動画生成AI「Veo」などを開発しています。
テキストだけでなく、画像・音声・動画を同時に理解・生成する「マルチモーダル処理」において圧倒的な強みを持ちます。
動画解析や複雑なメディア処理を行うAI開発など、汎用LLMでは対応しづらいタスクにおいて、Google Cloud (Vertex AI) 経由でその能力を活用できます。
Googleエコシステムとの親和性を重視する企業向けです。
主にGoogle Cloud (Vertex AI) 上での利用となり、使用したノード時間や処理量に応じた従量課金となります。
特定の最新モデルや共同研究利用の詳細については、お問い合わせが必要です。

画像出典元:「Hugging Face」公式HP
世界中の開発者がAIモデルやデータを共有する「AI界のGitHub」です。
Llama 3 (Meta)などの高性能なオープンソースモデルのホスティング場所として事実上の標準となっており、モデルのバージョン管理、共有、デプロイ機能(Inference Endpoints)を一貫して提供します。
オープンソースモデルを活用し、モデルを自社で育てていく前提の開発体制に適しています。
チーム開発や継続的改善を行う場合に、運用効率を最大化できます。
料金体系は以下の通りです。
推論エンドポイント: 使用するGPUインスタンスに応じた時間単位の従量課金
実際にこれらのツールを組み合わせて、「社内データを検索して回答するAI (RAG)」を作る場合のセットアップ例を見てみましょう。
社内ドキュメントをSnowflakeに集約・整理します。
不足している外部データ(業界ニュースなど)がある場合、Bright Dataを使って収集し統合します。
整理したテキストデータを、AIが検索しやすい「ベクトルデータ」に変換し、データベースに保存します。
検索リクエストを処理するためのサーバーとして、AWSのGPUインスタンスを用意します。
※コスト重視なら推論特化チップを選択
ユーザーからの質問に関連するデータを検索し、その内容をOpenAI (GPT-4 API) に渡して、自然な日本語の回答を生成させます。
一般的なWebサービス向けインフラとAI開発向けインフラの決定的な違いは、処理の負荷構造と扱うデータ量にあります。
従来のCPU中心のサーバーは、ディープラーニング特有の大規模な並列計算処理を前提としておらず、学習に数ヶ月を要するケースも珍しくありません。
また、大量のデータをリアルタイムで読み書きする必要があるため、ストレージ(保存領域)の読み書き速度もボトルネックになりがちです。
「とりあえず既存のクラウドサーバーで始める」という判断は、開発スピードの遅延やコストの増大を招く主な要因となります。
「何を作りたいか」によって、求められるインフラのスペックは異なります。
代表的な3つのユースケースから、必要な要件を逆引きしてみましょう。
自社独自のLLM(大規模言語モデル)を一から構築したり、既存モデルを追加学習(ファインチューニング)させたりする場合、膨大な計算能力が必要です。
推奨要件 :
メモリ帯域幅が広いHBM(広帯域メモリ)を搭載したハイエンドGPU (NVIDIA H100、A100など)を複数台連結させたクラスター環境が必須
注意点 :
計算が数週間続くこともあるため、途中で止まらない安定性と、万が一中断しても途中から再開できるチェックポイント機能が重要
このフェーズでは、AIインフラの中でもCompute Layerがボトルネックになりやすく、GPUの性能と台数がそのまま開発スピードを左右します。
社内ドキュメントを検索して回答を生成するRAG(検索拡張生成)や、自律的にタスクをこなすAIエージェントの場合、学習よりも「検索」と「応答速度」が重視されます。
推奨要件 :
文章の意味をベクトル(数値)化して高速検索できるベクトルデータベースと、推論処理に最適化されたコスト効率の良いGPU(NVIDIA L40Sや推論特化型チップ)の組み合わせが有効
注意点 :
ユーザーの待ち時間を減らすため、ネットワークの遅延(レイテンシ)が少ない国内リージョンのサーバーを選ぶことが望ましい
RAGやAIエージェント開発では、ComputeよりもData Layer(検索基盤)の設計が成果を左右します。
金融機関や医療機関など、データを外部に出せない環境でAIを活用する場合、セキュリティが最優先事項となります。
推奨要件 :
データセンターが国内にあり、日本の法律が適用される国産クラウドや、インターネットから隔離された閉域網接続が可能なサービスが適している
政府のセキュリティ評価制度であるISMAP(イスマップ)に登録されているかも重要な選定基準
このケースでは、性能や価格よりもデータ主権と法的リスク管理が優先されるため、海外GPUクラウドが最適解にならない場合もあります。
スペックと月額料金だけで比較すると、導入後に思わぬトラブルに見舞われることがあります。
契約前に必ず確認すべき3つのポイントを挙げます。
多くのクラウドサービスでは、データをクラウドに「入れる」時は無料でも、クラウドから「出す」時(ダウンロードや別サービスへの転送)に課金されるケースが一般的です。
AI開発ではテラバイト級のデータを扱うため、このデータ転送コスト(Egressコスト)だけで月額数百万円に達することも珍しくありません。
データ転送量が定額、あるいは無料のサービスを選ぶことが、長期的なコスト削減につながります。
世界的なGPU不足により、「契約したのにサーバーが割り当てられない」という事態が頻発しています。
確実にリソースを確保するためには、特定期間の利用を確約する「リザーブ契約(予約契約)」が必要な場合があります。
ただし、開発が予定より早く終わったり、頓挫したりした場合でも料金が発生し続けるリスクがあるため、プロジェクトのスケジュール精度を高めることが求められます。
海外ベンダーの支払いはドル建てが基本です。
円安が進行すると、利用料が変わらなくても日本円での支払額が急増し、予算を圧迫する可能性があります。
予算管理を厳格に行いたい場合は、日本円で固定料金が設定されている国内ベンダーを選ぶのが安全です。
トラブル時に日本語でサポートを受けられる点も、開発現場にとっては大きな安心材料となります。
読者の皆様から寄せられる、「具体的なシチュエーションでの迷い」にお答えします。
汎用クラウドがおすすめ :
既に社内システムがAWSやAzureにあり、セキュリティ設定やアカウント管理を統一したい場合。
また、データベースや認証機能など、GPU以外の機能もフル活用してアプリ開発をする場合。
特化型クラウドがおすすめ :
「LLMの事前学習」や「大規模な3Dレンダリング」など、とにかく大量のGPUパワーが必要な場合。
余計な機能がない分、同じ予算でより高性能なGPUを確保できます。
特化型クラウドは「ベアメタル(OSが入っただけのサーバー)」に近い状態で提供されることが多く、ネットワーク設定やセキュリティ構築を自力で行うスキル(Kubernetesの知識など)が求められる場合があります。
エンジニアリソースが限られている小規模チームであれば、多少割高でもAWSのマネージドサービス(SageMakerなど)やOpenAIなどのAPI利用から始める方が、結果的に開発スピードは速くなります。
AIインフラは「疎結合(必要なパーツだけをつなぐ)」がトレンドです。
アノテーションが必要なら:
Scale AI だけを契約し、作成したデータをお手持ちのサーバーにダウンロードして使います。
ベクトル検索が必要なら:
インフラを立てずに利用できる Pinecone や、Snowflake のベクトル機能などをAPI経由で利用するのが効率的です。
NVIDIA H100などのトップエンドモデルは、年単位の予約待ちや高額なデポジット(前払金)が必要なケースがあります。
しかし、推論用途であれば「L40S」や「A10G」、前世代の「A100」でも十分な性能を発揮します。
また、クラウドベンダーによっては「リザーブ(予約枠)契約」を結ぶことで優先確保してくれる場合があるため、Web上の在庫表記だけで諦めず、直接問い合わせることが重要です。
AI開発を成功させるには、従来のITインフラの延長ではなく、用途に即したAI基盤の選定が欠かせません。
現在は、Compute・Data・Modelの各レイヤーで最適なサービスを組み合わせる「ベスト・オブ・ブリード」が主流となりつつあります。
重要なのは、自社のフェーズが学習・推論・データ整備のどこにあるのかを見極め、その要件に合う基盤を選ぶことです。
特にGPUは需給が逼迫しており、Web上の情報だけでは判断が難しい状況です。
最新の在庫状況や最適構成を把握するためにも、早い段階で専門家に相談しましょう。
現実的な選択肢を確認した上で意思決定を進めることが、結果的に開発スピードとコスト最適化につながります。
画像出典元:O-dan


